블로그를 보다 유익한 정보가 있어서 스크랩 해봅니다.
정말 도움 되는 글 같아요. 본문 내용입니다.

어제 Synthesio Coffee Team은 Percona 5.6에서 Percona 5.7로 22TB MySQL Cluster 업그레이드를 완료했습니다. 우리는 이미 대부분의 클러스터를 업그레이드 했고 시간이 걸리는 것을 알고 있었지만 9개월이나 걸릴 것으로 생각하지는 않았습니다. 이것은 다운타임 없이 거대한 데이터베이스 클러스터를 마이그레이션하는 것에 관해 우리가 배웠던 것입니다.
초기 설정
우리의 데이터베이스 클러스터는 고전적인 고 가용성 3+1 노드 토폴로지로서 HAProxy를 이용합니다. 이것은 Systemd없이 Debian Jessie에서 4.9.1 커널 (처음에는 4.4.36)에서 실행됩니다. 이 서버는 20 core Dual Xeon E5-2260 v3 (256GB RAM) 및 36*4TB 하드 드라이브(RAID10)를 갖추고 있습니다. 처리량은 약 1억건 / 일이며, insert 및 update가 혼합되어 있습니다.
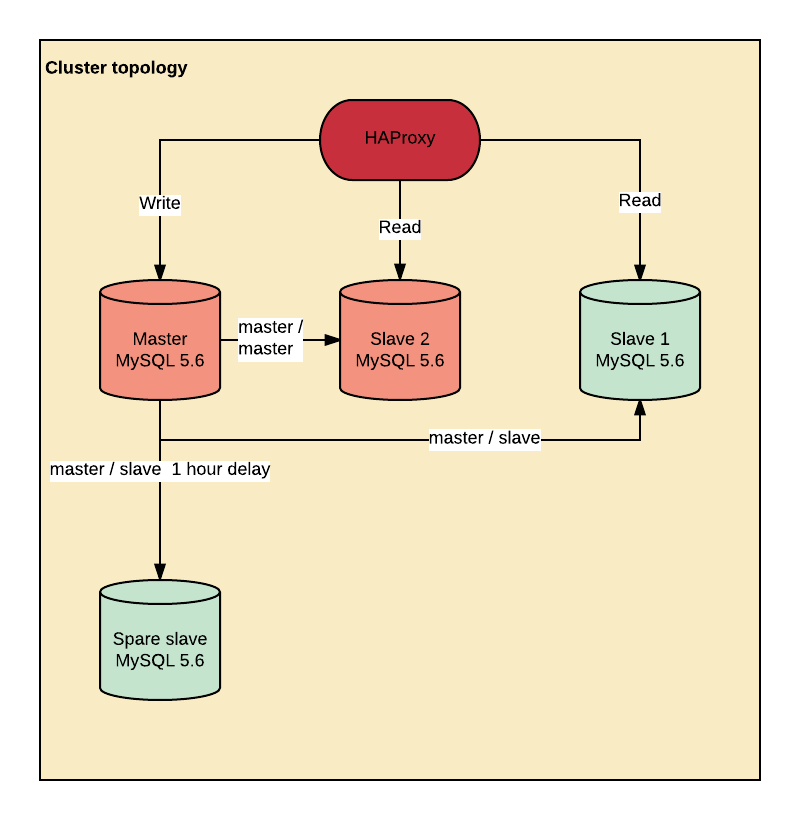
클러스터 디자인 자체에는 특별한 것이 없습니다.
- 2서버는 마스터/ 마스터로 구성되지만 쓰기는 메인 마스터에서만 수행됩니다.
- 읽기는 HAProxy를 통해 마스터 및 두 슬레이브에서 수행됩니다. 단 복제가 지연되는 슬레이브는 사용하지 않도록 설정되어 있습니다.
- 여분의 슬레이브는 Bobby Tables이 우리 서버와 함께 작동 할 경우 MASTER_DELAY를 1시간으로 설정하여 오프 사이트에서 실행됩니다.
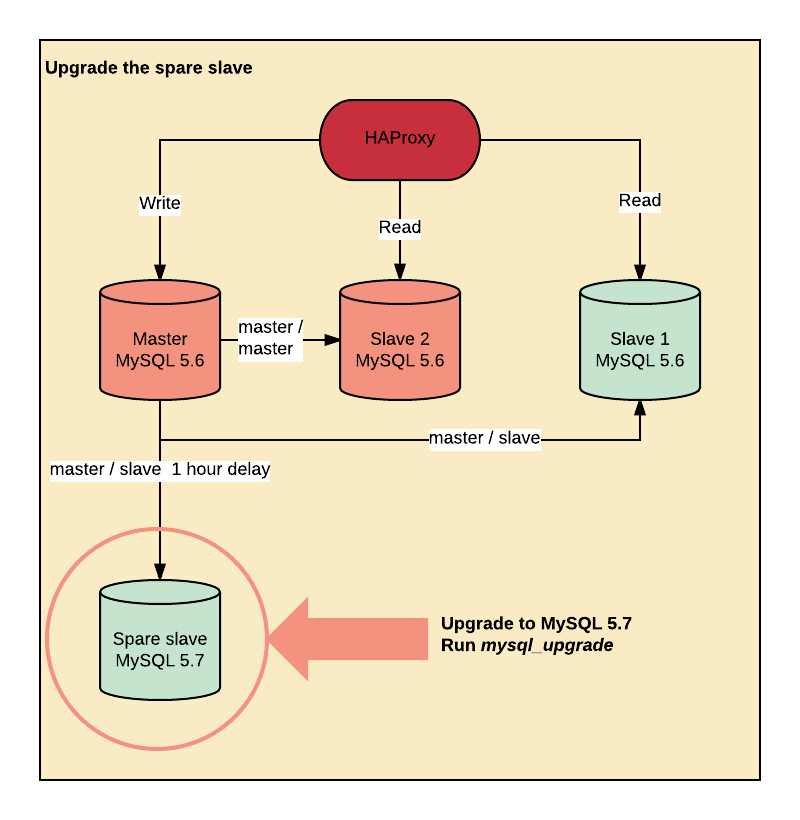
1단계 : mysql_upgrade의 지옥에서
Percona Debian 패키지를 사용하여 예비 호스트를 MySQL 5.7로 업그레이드 했습니다.
2단계 : 2개의 새로운 MySQL 5.7 슬레이브 추가하기
이렇게하기 전에 클러스터에 GTID가 활성화되어 있는지 확인하십시오. GTID를 사용하면 복제를 몇 번 재구성 할 때 많은 시간과 골칫거리를 줄일 수 있었습니다.

3단계 : 복제 따라 잡기 (다시)
다시 한 번 우리는 복제에 늦었습니다. 필자는 지연된 MySQL 복제를 수정하는 것에 대해 이미 썼습니다. 다음 구성을 적용하기 전에 장단점을 주의 깊게 읽으십시오.
STOP SLAVE;
SET GLOBAL sync_binlog=0;
SET GLOBAL innodb_flush_log_at_trx_commit=2;
SET GLOBAL innodb_flush_log_at_timeout=1800;
SET GLOBAL slave_parallel_workers=40;
START SLAVE;
두 호스트의 복제본을 잡는 데는 보통 2~3주 정도 소요되었기 때문에 우리는 보통보다 훨씬 많은 쓰기 작업을 수행했습니다.
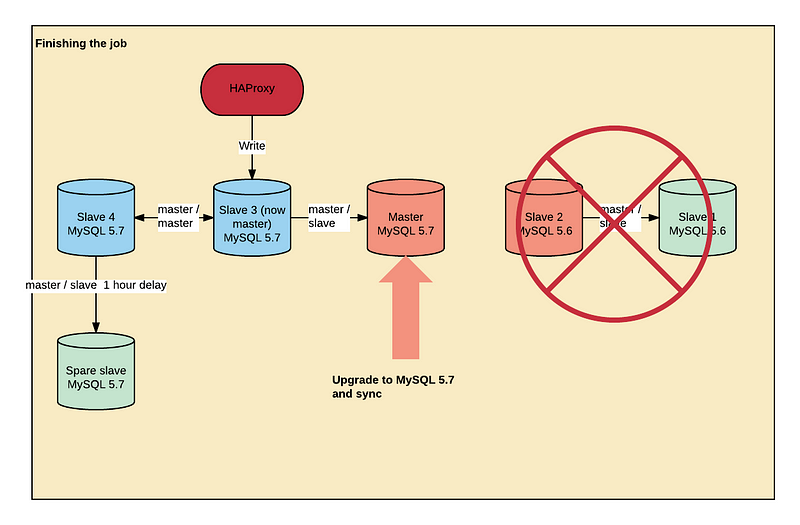
4단계 : 작업을 끝내다
마이그레이션이 거의 완료되었습니다. 몇가지 할 일이 남아있었습니다.
우리는 HAProxy를 재구성하여 슬레이브 3에 대한 쓰기를 전환시켰는데, 사실상 새로운 마스터가 되고 슬레이브 4에서 읽습니다. 그런 다음 플랫폼에서 모든 쓰기 프로세스를 다시 시작하여 나머지 연결을 종료합니다.
5분 후, 슬레이브 3은 마스터에서 모든 것을 따라 잡고 복제를 중단했습니다. 롤백해야하는 경우를 대비하여 마스터에서 마지막 트랜잭션 ID를 저장햇습니다.
그런 다음 슬레이브 3를 슬레이브 4의 슬레이브로 재구성하여 마스터 / 마스터 구성에서 다시 실행합니다.
우리는 MySQL 5.7에서 마스터를 업그레이드하고 innobackupex를 다시 실행하여 슬레이브 3의 슬레이브로 만들었습니다. 복제가 따라 잡기까지 며칠이 걸렸고 어제 클러스터에 마스터를 다시 추가했습니다.
일주일 후 우리는 더이상 쓸모없는 슬레이브 1과 슬레이브 2를 버렸습니다.