원문 : https://blog.naver.com/ghostlover23/221644176875

관계형 데이터베이스(RDBMS)의 데이터를 엘라스틱서치로 저장하면 데이터의 검색을 빠르게 할 수 있는 여러 가지 작업이 자동으로 이루어집니다. 엘라스틱서치는 데이터를 인덱싱(indexing)하고 '샤드'라는 단위로 데이터를 쪼개서 여러 데이터 노드에 분산을 시키고, 만약에 복제본(replica) 세팅이 1 이상이면 일종의 read replica를 생성해서 역시 여러 데이터 노드에 분산시켜서 QPS를 향상시킵니다.
일단 엘라스틱서치에 인덱싱이 되면 강력한 Query api(https://www.elastic.co/guide/en/elasticsearch/reference/current/full-text-queries.html)를 통해서 풀텍스트 검색(full text search)을 비롯한 다양한 검색을 수행할 수 있어서 많은 사용자들이 RDBMS와 함께 연동해서 사용하고 있습니다.
최근에는 RDBMS에 저장되어 있는 정형 데이터와 각종 웹서버 로그와 같은 비정형 데이터를 통합해서 상관분석하는 용도를 위해서 엘라스틱서치를 일종의 애쟈일 데이터마트(agile data mart)로 활용하는 사례도 많아지고 있습니다.
이런 여러 가지 시나리오를 위해서는 RDBMS의 데이터를 엘라스틱서치와 싱크(sync)하는 방법이 필요합니다. 이번 포스트에서는 엘라스틱스택(ELK스택)의 ETL 플랫폼인 로그스태시를 이용해서 효율적으로 데이터베이스의 레코드(records)를 엘라스틱서치로 가져오고 업데이트된 데이터가 있으면 엘라스틱서치로 싱크하는 방법을 알아 보겠습니다. MySQL로 예로 들었지만 다른 RDBMS에도 적용될 수 있는 방법입니다.
샘플은 엘라스틱서치 클러스터와 키비나가 설정된 환경에서 Dev Tools > Console에서 실행할 수 있습니다.
로그스태시는 다양한 데이터소스와 ETL 방법을 수용할 수 있도록 input plugin, filter plugin, output plugin과 같은 플러그인 구조로 되어 있습니다. MySQL을 엘라스틱서치와 싱크(Sync)하기 위해서 로그스태시의 jdbc input plugin(https://www.elastic.co/guide/en/logstash/current/plugins-inputs-jdbc.html)을 활용하겠습니다.
로그스태시의 jdbc input plugin은 주기적으로 MySQL을 폴링(polling)해서 마지막 작업 다음에 새로 추가되거나 수정된 레코드가 있으면 엘라스틱서치로 인덱싱할 수 있습니다.
RDBMS와 정확하게 싱크되기 위해서는 MySQL의 레코드가 엘라스틱서치에 인덱싱이 될 때, 엘라스틱서치의 문서 아이디 필드(_id field)가 MySQL의 "id" 필드로 맵핑되어야 합니다.
그리고 MySQL에 하나의 레코드가 추가되거나 수정되면 이 레코드는 추가 혹은 수정된 시간(insertion or update time)을 저정하는 하나의 필드를 가지고 있어야 합니다.
로그스태시는 이 필드를 통해서 마지막 작업 이후에 추가되거나 수정된 레코드들을 식별해서 가져 올 수가 있습니다.
위 두가지 조건이 충족되면 로그스태시는 주기적으로 추가 및 수정된 레코드들을 식별해서 엘라스틱서치와 싱크시킬 수가 있습니다.
샘플 MySQL 셋업
아래와 같이 MySQL 데이터베이스와 테이블을 설정합니다.
CREATE DATABASE es_db;
USE es_db;
DROP TABLE IF EXISTS es_table;
CREATE TABLE es_table (
id BIGINT(20) UNSIGNED NOT NULL,
PRIMARY KEY (id),
UNIQUE KEY unique_id (id),
client_name VARCHAR(32) NOT NULL,
modification_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
insertion_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);싱크(sync) 작업을 위해 중요한 포인트는 아래와 같습니다.
id: id는 PRIMARY KEY와 UNIQUE KEY로 정의되어 있습니다. 이 id는 각 레코드를 식별하고 엘라스틱서치의 문서 아이디(_id)로 맵핑이 됩니다.
modification_time: 이 필드는 MySQL의 레코드가 추가되거나 수정되면 그 시간을 저장합니다.
insertion_time: 이 필드는 어떤 레코드가 처음 추가된 시간을 저장합니다.
MySQL 데이터 입력 및 수정
이제 MySQL에서 원하는 대로 레코드를 insert, update 혹은 upcert할 수 있습니다.
INSERT INTO es_table (id, client_name) VALUES (<id>, <client name>);
UPDATE es_table SET client_name = <new client name> WHERE id=<id>;
INSERT INTO es_table (id, client_name) VALUES (<id>, <client name when created> ON DUPLICATE KEY UPDATE client_name=<client name when updated>;로그스태시 파이프라인(pipeline)
로그스태시의 jdbc input plugin을 통해서 싱크(synchronization) 작업을 하기 위한 파이프라인 설정 파일은 다음과 같습니다.
input {
jdbc {
jdbc_driver_library => "<path>/mysql-connector-java-8.0.16.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://<MySQL host>:3306/es_db"
jdbc_user => <my username>
jdbc_password => <my password>
jdbc_paging_enabled => true
tracking_column => "unix_ts_in_secs"
use_column_value => true
tracking_column_type => "numeric"
schedule => "*/5 * * * * *"
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW()) ORDER BY modification_time ASC"
}
}
filter {
mutate {
copy => { "id" => "[@metadata][_id]"}
remove_field => ["id", "@version", "unix_ts_in_secs"]
}
}
output {
# stdout { codec => "rubydebug"}
elasticsearch {
index => "rdbms_sync_idx"
document_id => "%{[@metadata][_id]}"
}
}
싱크 작업을 위해서 중요한 포인트는 다음과 같습니다.
tracking_column: 이 필드(unix_ts_in_secs)는 MySQL에서 로그스태시가 읽은 마지막 레코드를 식별하기 위해서 사용되며 .logstash_jdbc_last_run에 저장됩니다. 이 값은 다음 번에 로그스태시가 레코드를 읽어 올 때, SELECT 문에서 “:sql_last_value”로 참조할 수 있어서 이 시간 이후로 싱크 작업이 이루어지도록 설정하는 데 사용됩니다.
unix_ts_in_secs: 이 필드는 SELECT 문에서 “modification_time”을 저장하고 tracking_column으로 사용됩니다.
sql_last_value: 이 값은 일종의 built-in parameter 로서 .logstash_jdbc_last_run에서 읽은 시간을 저장하고 있습니다.
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW()) ORDER BY modification_time ASC"WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW())
WHERE절에서 이미 처리된 이후의 레코드들을 식별하는 데 사용이 됩니다.
schedule: 일반적인 크론(cron) 형식을 이용해서 얼마나 자주 로그스태시가 폴링(polling)을 할 것인지 설정합니다. 이 예제에서는 5초 간격으로 실행하도록 설정했습니다.
modification_time < NOW(): 로그스태시가 폴링(polling)한 현재 시간을 지정해서 정확한 싱크가 이루어 지기 위해서 설정합니다.
(뒤에 정확한 싱크를 위한 이론적인 면을 더 설명하겠습니다.)
filter: fileter plugin은 심플하게 MySQL의 "id"를 엘라스틱서치의 메타데이터인 문서 아이디(_id)로 복사를 합니다. 그리고 실제로 엘라스틱서치에 필드로 인덱싱할 필요가 없는 필드들(“id”, “@version”, and “unix_ts_in_secs”)을 삭제합니다.
filter {
mutate {
copy => { "id" => "[@metadata][_id]"}
remove_field => ["id", "@version", "unix_ts_in_secs"]
}
}정확한 싱크(Sync) 작업을 위해 고려해야 할 점
WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW())WHERE 절에서 modification_time < NOW() 가 추가로 설정한 이유를 살표 보겠습니다. 일반적으로 에지 문제(edge problem)으로 알려져 있는 데 직관적으로 와닿지 않기 때문에 문제가 생기는 2가지 시나리오를 살펴 보고 modification_time < NOW()를 통해서 어떻게 문제가 해결되는 지 보도록 하겠습니다.
MySQL이 1초에 2개의 문서를 추가하고 로그스태시가 5초에 한 번씩 가져 오는 케이스를 상정해 보겠습니다.
UNIX_TUMESTAMP(modification_time) > :sql_last_value만 설정했을 때
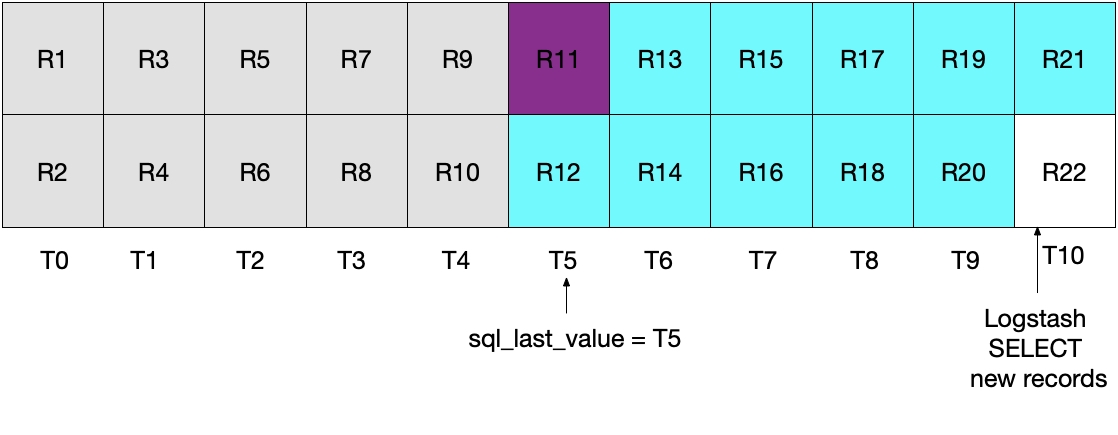
아래 그림에서 T가 시간이고 R이 추가된 레코드입니다.
MySQL에서 R11번까지 추가가 되고 로그스태시가 폴링(Polling)을 시작합니다.
로그스태시는 R11번까지 엘라스틱서치에 인덱싱을 하고 나서 R12가 MySQL에 추가될 수가 있습니다.
이 때 sql_last_value = T5로 설정이 됩니다.
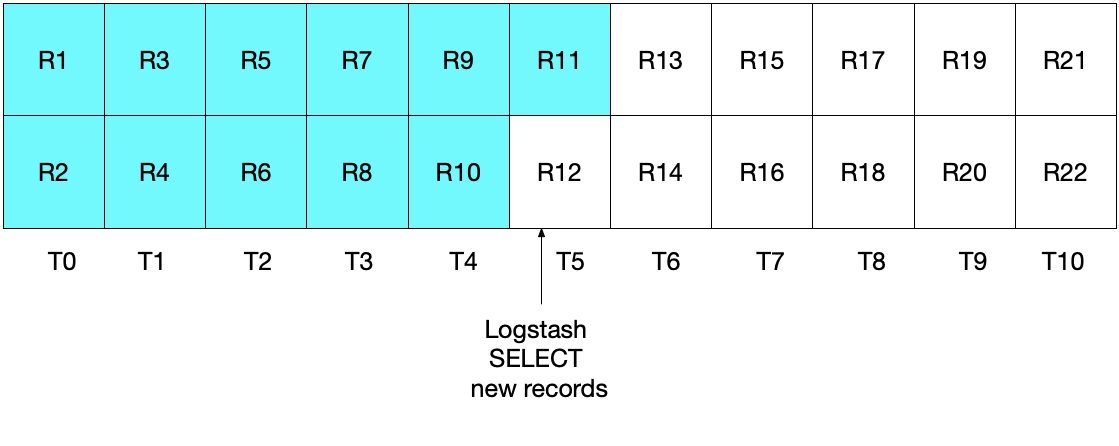
두 번째 폴링에서는 WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value)에 따라서 R13번 부터 읽어오기 시작합니다.
이 상황에서 R12는 읽지 못 하게 되는 edge problem이 발생합니다.
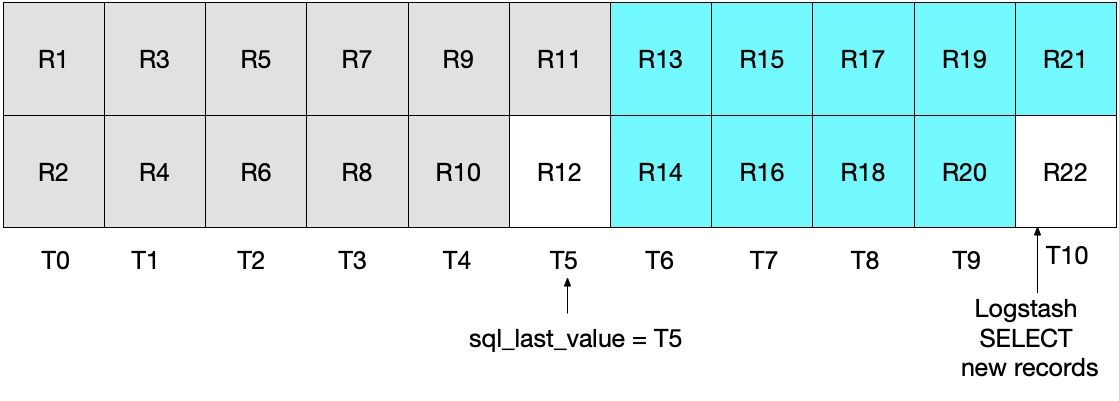
UNIX_TUMESTAMP(modification_time) >= :sql_last_value만 설정했을 때
이 문제를 해결하기 위해서 UNIX_TIMESTAMP(modification_time) >= :sql_last_value를 설정했을 때는 어떤 문제가 발생하는 지 보겠습니다. 위와 마찬가지로 처음 로그스태시가 폴링(polling)을 할 때 R11까지 읽어 들여서 sql_last_value = T5로 설정을 하고 이 후에 R12가 MySQL에 추가가 됩니다.
두 번째 실행해서는 R11이 중복되서 보내지는 edge problem이 여전히 발생합니다.
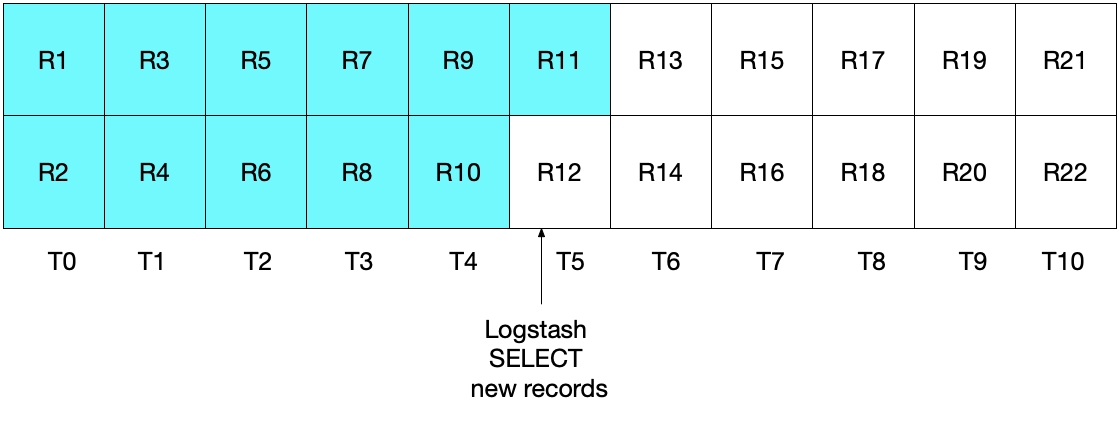
modification_time < NOW()가 추가되었을 때 (해결책)
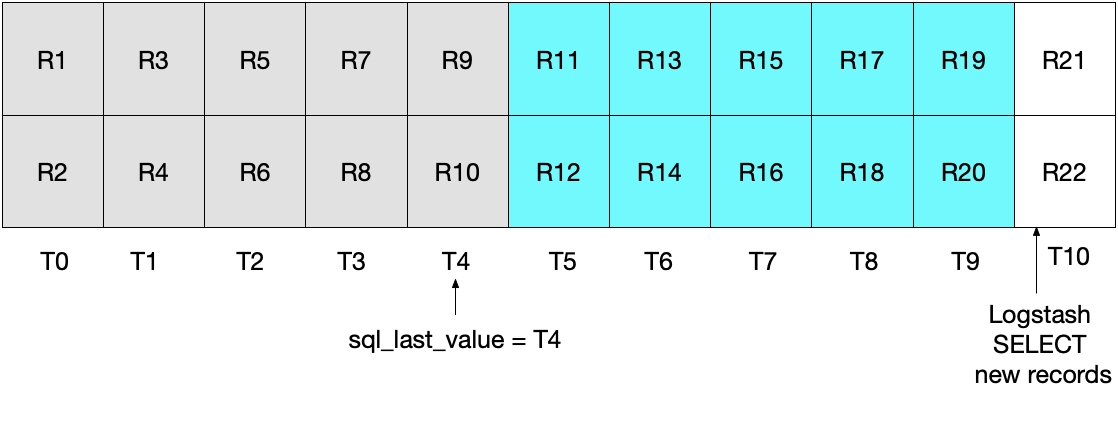
이번에는 T5에 로그스태시가 첫 번째 폴링(polling)을 실행했을 때 modification_time < NOW()때문에 R10까지만 엘라스틱서치에 인덱싱이 되고 sql_last_value = T4로 설정이 됩니다.
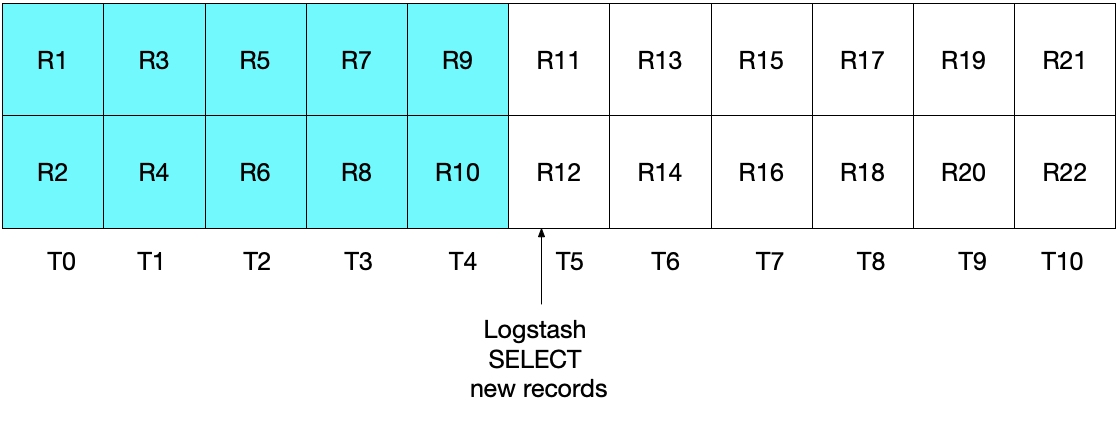
두 번째 실행이 될 때는 sql_last_value = T4이기 때문에 R11부터 중복없이 싱크가 이루어지면서 edge problem을 해결할 수 있습니다.
샘플 데이터로 싱크(sync) 작업 테스트
INSERT INTO es_table (id, client_name) VALUES (1, 'Jim Carrey');
INSERT INTO es_table (id, client_name) VALUES (2, 'Mike Myers');
INSERT INTO es_table (id, client_name) VALUES (3, 'Bryan Adams');3개의 레코드를 MySQL에 추가한 다음에 키바나의 Dev console에서 확인해 보면 레코드가 인덱싱된 것을 확인할 수 있습니다.
GET rdbms_sync_idx/_search
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "rdbms_sync_idx",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"insertion_time" : "2019-06-18T12:58:56.000Z",
"@timestamp" : "2019-06-18T13:04:27.436Z",
"modification_time" : "2019-06-18T12:58:56.000Z",
"client_name" : "Jim Carrey"
}
},
Etc …
이제 1번 레코드를 업데이트해서 다시 엘라스틱서치의 인덱스를 확인해 보겠습니다.
UPDATE es_table SET client_name = 'Jimbo Kerry' WHERE id=1;
GET rdbms_sync_idx/_doc/1
{
"_index" : "rdbms_sync_idx",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"insertion_time" : "2019-06-18T12:58:56.000Z",
"@timestamp" : "2019-06-18T13:09:30.300Z",
"modification_time" : "2019-06-18T13:09:28.000Z",
"client_name" : "Jimbo Kerry"
}
}인덱스를 보면 버전 넘버(_version)가 2로 업데이트가 되었고, modification_time이 insertion_time과 달라졌고 내용도 업데이트가 된 것을 확인할 수 있습니다.
만약에 레코드를 삭제하는 경우에도 엘라스틱서치와 싱크하기 위해서는 이른바 soft delete를 사용하는 방법이 있겠습니다.
간단하게 삭제 작업에 대한 정보를 저장할 is_deleted 필드를 MySQL에 두어서 삭제 명령으로 바로 레코드를 삭제하는 것이 아니라 is_deleted 필드만 true로 입력을 하고 나중에 배치 작업을 통해서 MySQL과 엘라스틱서치에서 별도로 is_deleted 필드가 있는 레코드와 인덱스를 벌크로 삭제하는 방법입니다.
그 외에는 CRUD 명령이 실행되면 데이터베이스에 반영하는 것과 동시에 메시지큐(Message Queue)에 명령어를 보내고 로그스태시에서 해당하는 input plugin에서 명령어를 읽어 와서 엘라스틱서치에 반영하는 방법이 있습니다.


